


 Eng
Eng  日本語
日本語 Br
Br De
DeEverything you know about application testing applies for legacy transformation projects, from unit tests to black/white box testing, test plan, et cetera… And when you are done with all these comes the hard part: proof of identity.
In order to understand testing in a legacy modernization project we have to understand how automated language conversion and modernization works and in which step testing takes place.
Application transformation is an iterative process. We take the legacy code, analyze, and parse it, convert to Java, build, test and when some tests don’t pass, we modify the conversion engine. The process looks like this.
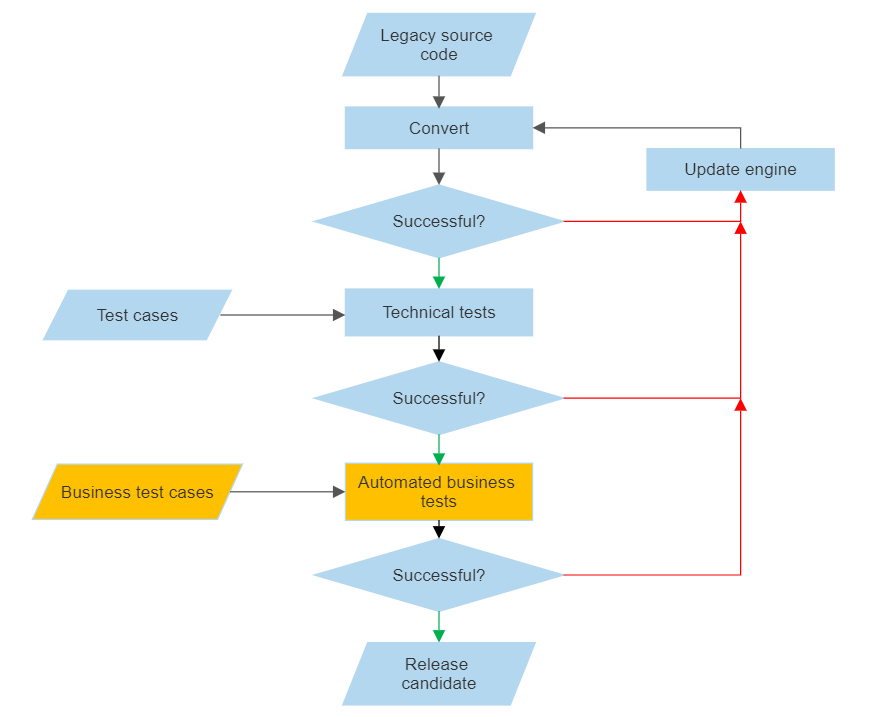
Conversion flow
This blog post is addressing the little orange pieces.
The fundamental issue of legacy conversion projects: how can we decide the converted application does exactly what the legacy application did. When we talk about what exactly means, it is not like 2+2=4, more like 2.00034 + 2.00066 = 4.00, if the underlying legacy language implementation dictates so. Rounding, truncation, precision, over/underflow handling are issues to consider. There may be differences between mainframe and open system implementations of legacy languages. There are bugs in legacy implementations that we must implement verbatim. (Yes, we have surprised(?) renown vendors with bugs not once.)
An exact behavior a bit more formally can be defined as producing the same output using the same input. In essence we have to establish a known state of the legacy system, we call it the baseline. Then we capture and record sequences of input, process it and capture and record the output. This may take a form of logs, sequences of keystrokes, screenshots, protocol messages (e.g., http conversations), datasets, database dumps, or anything that matters and provides meaningful information for comparison. Simple. We run the same business tests against the converted java application and when the output matches the baseline systems output, we’re good. But are we?!
The challenges – as always – are plentiful.
The customer has access to the legacy system. They know their own business; they know what’s important. They must understand that the success of the project hinges around this exactness we discussed above. If the customer creates nine test cases that the tests must pass, it is their responsibility. If they create 499, it makes no difference to us when we run the test cases – other than we potentially find more discrepancies – but it makes a huge difference in what we can assume about the conversion quality. Also, the test cases should cover the full breadth of the applications. The fidelity will never be 100% exactly but it will asymptotically approach 100% the more test cases we have. Of course, an equilibrium can be established between the risk of letting bugs slip through versus the costs of creating new test cases and the costs of evaluating them. Repeatedly.
This blog post does not touch on the role of the customer in details when it comes to creating meaningful test cases. But this one does.
A conversion project is not an overnight affair. The customers keep developing their system even after the contract for the conversion project is signed. Establishing a baseline can be challenging in this environment. A wrong move and half of the original test case recordings must be discarded and forced to be taken again. Well. Which half exactly?
Speed: for a new test run the baseline must be restored in the testing system. This restore must be reasonably fast. Define reasonably!
Another note on speed: performance. The converted code may not be as fast as the original one at the beginning of the testing. We are not talking here small batches that run for 5 instead of 3 seconds. Unless it is repeatedly called 5000 times. This difference may be critical during testing, particularly if the test environment is not anywhere near in performance to the production environment. To be able to detect performance issues we must have a comparable environment to the production one. Or the other way around: measured performance in a test environment dictates the requirements for the production environment. (Autoscaling, anyone?)
Tools: We need bimodal tools, meaning, capture in baseline, replay in converted systems. Usual tools like Selenium, Appium and alike won’t cut it.
This blog post does not discuss integration tests. That’s a whole new realm of challenges. Those tests happen at the customer’s site after release. But we cannot wait for the results of those tests because it may take forever and slows down development drastically. They introduce dependencies that we cannot control in-house. Think of the app accesses some data through FTP or APIs, or another app is called before/after. We need a much shorter cycle to be able to test in-house. The converted code must be isolated from these dependencies. The challenge here is that the customer must create these test cases for us.
And all these test processes must be automated because in a conversion project we run these continuously and use CPU for testing about tenfold more than for conversion and build. We use our AppTester to do the heavy lifting.